

Puede parecer que la tendencia de la IA sigue una trayectoria de publicidad y adopción similar a la de tendencias tecnológicas empresariales anteriores, como la nube y el aprendizaje automático, aunque es diferente en aspectos importantes, entre ellos: La IA requiere enormes cantidades de computación para los procesos que le permiten digerir y recrear datos no estructurados. La IA está cambiando la forma en que algunas organizaciones ven la estructura organizacional y las carreras. El contenido de IA que puede confundirse con fotografías u obras de arte originales está sacudiendo el mundo artístico y algunos temen que pueda usarse para influir en las elecciones. Aquí están nuestras predicciones para cinco tendencias en IA, que a menudo se refieren a modelos generativos, a las que debemos estar atentos en 2024. La adopción de IA parece cada vez más una integración con aplicaciones existentes. Muchos casos de uso de IA generativa que llegan al mercado para empresas y negocios se integran con aplicaciones existentes. en lugar de crear casos de uso completamente nuevos. El ejemplo más destacado de esto es la proliferación de copilotos, es decir, asistentes de IA generativa. Microsoft ha instalado copilotos junto a las ofertas de la suite 365, y empresas como SoftServe y muchas otras proporcionan copilotos para trabajos y mantenimiento industriales. Google ofrece una variedad de copilotos para todo, desde la creación de videos hasta la seguridad. Pero todos estos copilotos están diseñados para examinar el contenido existente o crear contenido que se parezca más a lo que un humano escribiría para trabajar. VER: ¿Google Gemini o ChatGPT son mejores para el trabajo? (TechRepublic) Incluso IBM pidió una revisión de la realidad sobre la tecnología de moda y señaló que herramientas como Smart Compose 2018 de Google son técnicamente «generativas», pero no se consideraron un cambio en la forma en que trabajamos. Una diferencia importante entre Smart Compose y la IA generativa contemporánea es que algunos modelos de IA actuales son multimodales, lo que significa que pueden crear e interpretar imágenes, vídeos y gráficos. “Yo diría que veremos mucha innovación al respecto (multimodalidad) en 2024”, dijo Arun Chandrasekaran, distinguido vicepresidente y analista de Gartner, en una conversación con TechRepublic. En NVIDIA GTC 2024, muchas empresas emergentes en la feria ejecutaron chatbots en los grandes modelos de lenguaje de Mistral AI, ya que los modelos abiertos se pueden usar para crear IA entrenada personalizada con acceso a los datos de la empresa. El uso de datos de capacitación patentados permite a la IA responder preguntas sobre productos, procesos industriales o servicios al cliente específicos sin necesidad de introducir información patentada de la empresa en un modelo capacitado que podría publicar esos datos en la Internet pública. Hay muchos otros modelos abiertos para texto y video, incluido Meta’s Llama 2, el conjunto de modelos de Stability AI, que incluye Stable LM y Stable Diffusion, y la familia Falcon del Instituto de Innovación Tecnológica de Abu Dhabi. «Existe un gran interés en llevar datos empresariales a los LLM como una forma de fundamentar los modelos y agregar contexto», dijo Chandrasekaran. La personalización de modelos abiertos se puede realizar de varias maneras, incluida la ingeniería rápida, la generación con recuperación aumentada y el ajuste fino. Agentes de IA Otra forma en que la IA podría integrarse más con las aplicaciones existentes en 2024 es a través de agentes de IA, que Chandrasekaran llamó “una bifurcación” en el progreso de la IA. Los agentes de IA automatizan las tareas de otros robots de IA, lo que significa que el usuario no tiene que solicitar modelos individuales específicamente; en cambio, pueden proporcionar una instrucción en lenguaje natural al agente, lo que esencialmente pone a su equipo a trabajar reuniendo los diferentes comandos necesarios para llevar a cabo la instrucción. El vicepresidente senior de Intel y director general de Network and Edge Group, Sachin Katti, también se refirió a los agentes de IA y sugirió en una sesión informativa previa a la conferencia Intel Vision celebrada del 9 al 11 de abril que la IA que delegue el trabajo entre sí podría realizar las tareas de departamentos enteros. . La generación de recuperación aumentada domina la IA empresarial La generación de recuperación aumentada permite a un LLM comparar sus respuestas con una fuente externa antes de proporcionar una respuesta. Por ejemplo, la IA puede comparar su respuesta con un manual técnico y proporcionar a los usuarios notas a pie de página que tienen enlaces directos al manual. RAG está destinado a aumentar la precisión y disminuir las alucinaciones. RAG proporciona a las organizaciones una forma de mejorar la precisión de los modelos de IA sin que la factura se dispare. RAG produce resultados más precisos en comparación con otras formas comunes de agregar datos empresariales a los LLM, ingeniería rápida y ajustes. Es un tema candente en 2024 y es probable que continúe siéndolo más adelante este año. Más cobertura de IA de lectura obligada Las organizaciones expresan silenciosas preocupaciones sobre la sostenibilidad. La IA se utiliza para crear modelos climáticos y meteorológicos que predicen eventos desastrosos. Al mismo tiempo, la IA generativa consume mucha energía y recursos en comparación con la informática convencional. ¿Qué significa esto para las tendencias de la IA? De manera optimista, la conciencia de los procesos que consumen mucha energía alentará a las empresas a fabricar hardware más eficiente para ejecutarlos o adaptar su uso. De manera menos optimista, las cargas de trabajo de IA generativa pueden seguir consumiendo enormes cantidades de electricidad y agua. De cualquier manera, la IA generativa puede convertirse en un tema que contribuya a los debates nacionales sobre el uso de la energía y la resiliencia de la red. La regulación de la IA ahora se centra principalmente en casos de uso, pero en el futuro, su uso de energía también puede estar sujeto a regulaciones específicas. Los gigantes tecnológicos abordan la sostenibilidad a su manera, como la compra de energía solar y eólica por parte de Google en determinadas regiones. Por ejemplo, NVIDIA promocionó el ahorro de energía en los centros de datos sin dejar de ejecutar IA mediante el uso de menos bastidores de servidores con GPU más potentes. El uso de energía de los centros de datos y chips de IA Los 100.000 servidores de IA que se espera que NVIDIA envíe a los clientes este año podrían producir entre 5,7 y 8,9 TWh de electricidad al año, una fracción de la electricidad que se utiliza en los centros de datos hoy en día. Esto es según un artículo del candidato a doctorado Alex de Vries publicado en octubre de 2023. Pero si NVIDIA por sí sola agrega 1,5 millones de servidores de IA a la red para 2027, como especula el artículo, los servidores usarían entre 85,4 y 134,0 TWh por año, lo que es un impacto mucho más grave. Otro estudio encontró que la creación de 1000 imágenes con Stable Diffusion XL genera aproximadamente tanto dióxido de carbono como conducir 4,1 millas en un automóvil promedio de gasolina. «Descubrimos que las arquitecturas generativas multipropósito son órdenes de magnitud más caras que los sistemas de tareas específicas para una variedad de tareas, incluso cuando se controla el número de parámetros del modelo», escribieron los investigadores Alexandra Sasha Luccioni y Yacine Jernite de Hugging. Face y Emma Strubell de la Universidad Carnegie Mellon. En la revista Nature, la investigadora de inteligencia artificial de Microsoft, Kate Crawford, señaló que el entrenamiento del GPT-4 utilizó alrededor del 6% del agua del distrito local. Cambian los roles de los especialistas en inteligencia artificial La ingeniería rápida fue una de las habilidades más populares en tecnología en 2023, y la gente se apresuró a traer a casa salarios de seis cifras por instruir a ChatGPT y productos similares para producir respuestas útiles. El revuelo se ha desvanecido un poco y, como se mencionó anteriormente, muchas empresas que utilizan mucho la IA generativa personalizan sus propios modelos. La ingeniería rápida puede convertirse en parte de las tareas habituales de los ingenieros de software en el futuro, pero no como una especialización, sino simplemente como una parte de la forma en que los ingenieros de software realizan sus tareas habituales. Uso de IA para ingeniería de software «El uso de IA dentro del dominio de la ingeniería de software es uno de los casos de uso de más rápido crecimiento que vemos hoy», dijo Chandrasekaran. “Creo que la ingeniería rápida será una habilidad importante en toda la organización en el sentido de que cualquier persona que interactúe con sistemas de IA (que seremos muchos de nosotros en el futuro) debe saber cómo guiar y dirigir estos modelos. Pero, por supuesto, la gente en ingeniería de software necesita comprender realmente la ingeniería rápida a escala y algunas de las técnicas avanzadas de la ingeniería rápida”. En cuanto a cómo se asignan las funciones de la IA, dependerá en gran medida de las organizaciones individuales. Queda por ver si la mayoría de las personas que realizan ingeniería rápida tendrán o no ingeniería rápida como título de trabajo. Títulos ejecutivos relacionados con la IA Una encuesta de ejecutivos de datos y tecnología realizada por Sloan Management Review del MIT en enero de 2024 encontró que las organizaciones a veces estaban recortando los puestos de directores de IA. Ha habido cierta “confusión sobre las responsabilidades” de los líderes hiperespecializados como la IA o los responsables de datos, y es probable que 2024 se normalice en torno a los “líderes tecnológicos generales” que crean valor a partir de los datos e informan al director ejecutivo, independientemente de dónde provengan esos datos. de. VER: Qué hace un jefe de IA y por qué las organizaciones deberían tener uno en el futuro. (TechRepublic) Por otro lado, Chandrasekaran dijo que los directores de datos y análisis y los directores de inteligencia artificial «no son frecuentes», pero han aumentado en número. Es difícil predecir si ambos seguirán siendo roles separados de CIO o CTO, pero puede depender de qué competencias centrales estén buscando las organizaciones y de si los CIO se encuentran equilibrando demasiadas otras responsabilidades al mismo tiempo. «Definitivamente estamos viendo que estos roles (oficial de IA y oficial de datos y análisis) aparecen cada vez más en nuestras conversaciones con los clientes», dijo Chandrasekaran. El 28 de marzo de 2024, la Oficina de Administración y Presupuesto de EE. UU. publicó una guía para el uso de IA dentro de las agencias federales, que incluía un mandato para que todas esas agencias designaran un Director de IA. El arte con IA y el vidriado contra el arte con IA se vuelven más comunes A medida que el software artístico y las plataformas de fotografías de archivo abrazan la fiebre del oro de las imágenes sencillas, los artistas y reguladores buscan formas de identificar el contenido de IA para evitar la desinformación y el robo. El arte con IA se está volviendo más común. Adobe Stock ahora ofrece herramientas para crear arte con IA y marca el arte con IA como tal en su catálogo de imágenes de archivo. El 18 de marzo de 2024, Shutterstock y NVIDIA anunciaron una herramienta de generación de imágenes 3D en acceso temprano. OpenAI promovió recientemente a cineastas que utilizan la fotorrealista Sora AI. Las demostraciones fueron criticadas por defensores de los artistas, incluido el director ejecutivo de Fairly Trained AI, Ed Newton-Rex, ex miembro de Stability AI, quien las llamó «Artistwashing: cuando solicitas comentarios positivos sobre tu modelo de IA generativa de un puñado de creadores, mientras entrenas en el trabajo de las personas». sin permiso/pago”. Es probable que a lo largo de 2024 se sigan desarrollando dos posibles respuestas a las obras de arte con IA: las marcas de agua y el vidriado. Arte de IA con marcas de agua El estándar líder para las marcas de agua proviene de la Coalición para la Procedencia y Autenticidad del Contenido, con la que OpenAI (Figura A) y Meta han trabajado para etiquetar imágenes generadas por su IA; sin embargo, las marcas de agua, que aparecen visualmente o en metadatos, son fáciles de eliminar. Algunos dicen que las marcas de agua no serán suficientes para prevenir la desinformación, particularmente en torno a las elecciones estadounidenses de 2024. La Figura A Los metadatos de una imagen generada por DALL-E muestran la procedencia de la imagen. VER: El gobierno federal de EE. UU. y las principales empresas de inteligencia artificial acordaron el año pasado una lista de compromisos voluntarios, incluida la marca de agua. (TechRepublic) Envenenamiento de arte original con IA Los artistas que buscan evitar que los modelos de IA se entrenen con arte original publicado en línea pueden usar Glaze o Nightshade, dos herramientas de envenenamiento de datos creadas por la Universidad de Chicago. El envenenamiento de datos ajusta las ilustraciones lo suficiente como para hacerlas ilegibles para un modelo de IA. Es probable que aparezcan más herramientas como esta en el futuro, ya que tanto la generación de imágenes mediante IA como la protección del trabajo original de los artistas seguirán siendo un foco de atención en 2024. ¿Está sobrevalorada la IA? La IA era tan popular en 2023 que inevitablemente fue sobrevalorada en 2024, pero eso no significa que no se le esté dando algún uso práctico. A finales de 2023, Gartner declaró que la IA generativa había alcanzado “la cima de las expectativas infladas”, un conocido pináculo de exageración antes de que las tecnologías emergentes se volvieran prácticas y normalizadas. Al pico le sigue el “punto más bajo de la desilusión” antes de volver a subir a la “pendiente de la iluminación” y, finalmente, a la productividad. Podría decirse que el lugar de la IA generativa en el pico o en el punto más bajo significa que está sobrevalorada. Sin embargo, muchos otros productos han pasado por el ciclo de exageración antes, y muchos finalmente alcanzaron la “meseta de productividad” después del auge inicial.
Etiqueta: nvidia Página 1 de 3

Google Cloud anunció una nueva suscripción empresarial para Chrome y una serie de complementos de IA generativa para Google Workspace durante la conferencia Cloud Next ’24, celebrada en Las Vegas del 9 al 11 de abril. En general, Google Cloud está poniendo su IA generativa Gemini en coloque todo lo que pueda; por ejemplo, la empresa está apostando por proporcionar infraestructura Vertex AI para la IA y el hardware de otras empresas, como la nueva CPU Axion. Asistimos a una sesión informativa previa para echar un vistazo temprano a las nuevas funciones y herramientas, incluido un servicio de video generativo de IA para uso en marketing y comunicaciones internas. A continuación se ofrece un resumen de lo que consideramos las noticias empresariales más impactantes de Google Cloud Next. Chrome Enterprise Premium agrega controles de seguridad Los navegadores empresariales pueden ser una tendencia creciente. El año pasado, Gartner predijo que los navegadores creados específicamente teniendo en cuenta la seguridad y el soporte a nivel empresarial alcanzarían una adopción generalizada para 2030. Google está contribuyendo con Chrome Enterprise Premium. Este nivel empresarial agrega un nivel adicional de seguridad a Chrome, mejorándolo con: Controles empresariales para la aplicación de políticas y administración de actualizaciones y extensiones de software. Informes de eventos y dispositivos. Informes de seguridad forense. Controles de acceso contextuales. Amenazas y protección de datos. Chrome Enterprise Premium está disponible hoy, 9 de abril, en cualquier lugar donde se ofrezca Chrome. Cuesta $6 por usuario por mes. Axion es la primera CPU basada en Arm de Google Algunos servicios de Google Cloud, como BigQuery, pronto se ejecutarán en los procesadores Google Axion, la primera CPU basada en Arm personalizada de Google para centros de datos (Figura A). Google Cloud dijo que Axion muestra un rendimiento un 50% mejor que las máquinas virtuales comparables basadas en x86 de la generación actual. Las instancias de Google Compute Engine, Google Kubernetes Engine, Dataproc, Dataflow, Cloud Batch y más estarán disponibles más adelante en 2024. Figura A Los procesadores Google Axion están destinados a ejecutar cargas de trabajo en la nube en centros de datos. Imagen: Google Cloud Vertex AI se basará en la Búsqueda de Google A partir del 9 de abril, los modelos entrenados en Vertex AI se basarán en la Búsqueda de Google. Esto podría resultar controvertido dependiendo exactamente de qué datos se utilicen para la capacitación. La conexión a tierra de la IA es parte de la tendencia de recuperación de generación aumentada, que evita las «alucinaciones» al comparar la IA con información genuina. Google Cloud dice que la conexión a tierra proporcionará a los modelos creados en Vertex AI «información nueva y de alta calidad». Más noticias y consejos de Google Una gran cantidad de adiciones de IA para los productos de seguridad de Google Otros anuncios de Google Cloud se centraron en agregar Gemini a los productos de seguridad, una medida posiblemente destinada a competir con la integración completa de Copilot por parte de Microsoft en sus suites de seguridad. Gemini AI ahora estará disponible en Google Security Operations (Figura B) y Threat Intelligence. En particular, Gemini podrá ayudar con las investigaciones en Chronicle Enterprise y Chronicle Enterprise Plus a partir de finales de abril. A partir del 9 de abril, los analistas de seguridad pueden utilizar Gemini para hablar en lenguaje natural con el software de inteligencia de amenazas de Mandiant. Figura B Un ejemplo del uso de Gemini en Operaciones de seguridad para investigar incidentes y alertas con chat conversacional en Chronicle Enterprise o Enterprise Plus. Imagen: Google Cloud Gemini en Security Command Center recibió un impulso de Gemini; A partir del 9 de abril, las funciones de IA en la vista previa pueden buscar amenazas basándose en indicaciones de lenguaje natural y resumir alertas y rutas de ataque. «Los ingenieros de detección pueden crear detecciones y guías con menos esfuerzo, y los analistas de seguridad pueden encontrar respuestas rápidamente con resúmenes inteligentes y búsquedas en lenguaje natural», dijo Ronald Smalley, vicepresidente senior de Operaciones de Ciberseguridad de Fiserv, en un comunicado de prensa de Google Cloud. «Esto es fundamental ya que los equipos de SOC continúan administrando volúmenes de datos cada vez mayores y necesitan detectar, validar y responder a eventos más rápido». Gemini Cloud Assist en los servicios de seguridad de Google Cloud ahora incluirá las siguientes capacidades impulsadas por IA en versión preliminar: Identidad y acceso recomendaciones de manejo para mejorar la postura IAM. Asistencia con la creación de claves de cifrado. Sugerencias sobre cómo implementar la protección informática confidencial. Cree videos con IA y más en las nuevas ofertas de Google Workspace Google presentó una nueva plataforma Workspace llamada Google Vids (Figura C), con la cual la IA generativa puede ayudar a los empleados a crear videos promocionales o informativos. Figura C Un usuario proporciona un guión como mensaje para darle a Google Vids una idea de lo que quiere que diga su video. Imagen: Google Cloud Primero, Google Vids creará un guión gráfico que el usuario podrá personalizar. Desde allí, Google Vids puede crear el video y agregar voz en off con voces AI preestablecidas o audio personalizado. Google Vids será una plataforma completamente nueva que convivirá junto con Docs Sheets y Slides. Se podrá acceder a los vídeos a través de Workspace Labs en junio. Más anuncios de Google Workspace Una herramienta de inteligencia artificial para resumir y traducir reuniones, que costará 10 dólares por usuario al mes. Clasificación y protección de archivos del complemento AI Security, que costará 10 dólares por usuario al mes. En Gmail, la IA habilitará las herramientas «Pulir mi borrador» y «Ayúdame a escribir», la última de las cuales se puede utilizar mediante comandos de voz en el móvil. Google Gemini llega a Chat y Docs para crear imágenes de portada. Vertex AI se integrará en Google Workspace. Extensión de HubSpot para Gemini para Google Workspace. Gemini 1.5 Pro llega a Vertex AI y Data Cloud Google anunció muchos cambios en el portafolio de Data Cloud en bases de datos y análisis de datos. La más importante fue la disponibilidad de Gemini 1.5 Pro en Vertex AI, que permite una ventana de contexto de un millón de tokens. VER: Todo lo que necesitas saber sobre Google Cloud Platform. (TechRepublic) Google continúa ampliando las integraciones y capacidades de Gemini: en la vista previa de hoy están Gemini en Looker y Gemini en BigQuery. Las nuevas características adicionales de BigQuery disponibles hoy en vista previa o vista previa privada incluyen información sobre documentos y audio de Vertex AI, incrustaciones y coincidencias de vectores, y más. Otros anuncios (en vista previa a menos que se indique lo contrario) incluyen: Google Gemini en bases de datos. Soporte vectorial e integración de LangChain en Bases de Datos. Soporte de vectores, soporte de lenguaje natural y gestión de puntos finales de modelos para AlloyDB. Acceso aislado a cargas de trabajo desde motores de análisis en Bigtable Data Boost. Capacidades ampliadas de recuperación ante desastres y mantenimiento en menos de dos segundos (en disponibilidad general) en Cloud SQL. Nuevo tamaño de instancia para Memorystore (en disponibilidad general) y compatibilidad con dos nuevas opciones de persistencia en Memorystore (en versión preliminar). Claves de cifrado administradas por el cliente en Cloud Firestore. TPU v5p entra en disponibilidad general El acelerador de IA TPU v5p de Google ahora está en disponibilidad general, lo que permite a las organizaciones usarlo para inferencia y capacitación de IA. Además, Google Kubernetes Engine ahora es compatible con TPU v5p. Avanzando en la hipercomputación y la computación en la nube, Google Cloud trabajará con el hardware de NVIDIA para impulsar la infraestructura de capacitación en inteligencia artificial de Google. Los anuncios del grupo de infraestructura en la nube incluyeron: A3 Mega VM con tecnología de GPU NVIDIA H100 Tensor Core para entrenamiento de IA a gran escala, disponibles de forma generalizada en mayo. Hyperdisk ML, un nuevo servicio de almacenamiento en bloque para cargas de trabajo de inferencia/servicio de IA, ya está disponible en versión preliminar. JetStream, un motor de inferencia de rendimiento y memoria optimizado para la formación LLM, está disponible hoy en GitHub. Dynamic Workload Scheduler, un servicio para administrar recursos en Google Cloud para optimizar las cargas de trabajo de IA según la capacidad informática, ahora está en versión preliminar. Duet AI para desarrolladores ahora es Gemini Code Assist. Competidores de Google Cloud El amplio catálogo de productos de Google significa que tiene muchos competidores en diferentes sectores. En el ecosistema de IA generativa y en el soporte empresarial en particular, compite y a menudo interopera con Copilot AI, AWS, IBM y SAP de Microsoft. El chip Axion en particular podría ayudar a Google a ingresar al espacio de chips para centros de datos dominado por Amazon y NVIDIA. TechRepublic cubre Google Cloud Next ’24 de forma remota.

Después de anunciar por primera vez la existencia del acelerador de IA Gaudi 3 el año pasado, Intel está listo para poner el chip en manos de los OEM en el segundo trimestre de 2024. Intel anunció esta y otras noticias, incluida una nueva marca Xeon 6 y un estándar Ethernet abierto para IA. cargas de trabajo, en una sesión informativa previa celebrada el 1 de abril antes de la conferencia Intel Vision, que se llevará a cabo del 8 al 9 de abril en Phoenix, Arizona. El acelerador de IA Gaudi 3 se enviará a Dell, Hewlett Packard Enterprise, Lenovo y Supermicro. El Gaudi 3 se lanzará con Dell, Hewlett Packard Enterprise, Lenovo y Supermicro como socios OEM. Intel Gaudi 3 estará disponible a través de proveedores en tres factores de forma: tarjeta intermedia, placa base universal o PCle CEM. Gaudi 3 tiene un tiempo de entrenamiento de modelos de lenguajes grandes un 40% más rápido en comparación con el chip H100 AI de NVIDIA y una inferencia en LLM un 50% más rápida en comparación con el NVIDIA H100, dijo Intel. Gaudi 3 puede enfrentarse cara a cara con el chip acelerador de IA recientemente anunciado por NVIDIA, Blackwell. Gaudi 3 es «altamente competitivo», afirmó Jeff McVeigh, vicepresidente corporativo y director general del Grupo de Ingeniería de Software de Intel. McVeigh señaló que aún no ha sido posible realizar pruebas en el mundo real para los dos productos. La nueva marca Xeon 6 llegará en el segundo trimestre. Los procesadores Xeon 6, que vienen en las dos variantes de Performance-core y Efficient-core, se enviarán pronto. Los procesadores E-core se enviarán en el segundo trimestre de 2024, y poco después los procesadores P-core. Las dos variantes de los procesadores Xeon 6 comparten la misma base de plataforma y pila de software. El núcleo Performance está optimizado para cargas de trabajo de IA y de computación intensiva, mientras que el núcleo Efficient está optimizado para la eficiencia en las mismas cargas de trabajo. El procesador Intel Xeon 6 con E-core muestra una mejora de rendimiento por vatio de 2,4 veces en comparación con las generaciones anteriores y una mejora de rendimiento por bastidor de 2,7 veces en comparación con las generaciones anteriores. El procesador Xeon 6 muestra un marcado ahorro de energía en comparación con el procesador Intel Xeon de segunda generación debido a que necesita menos bastidores de servidores, lo que supone una reducción de energía de hasta 1 megavatio. La tarjeta de interfaz de red admite el estándar abierto de Internet para cargas de trabajo de IA. Como parte del esfuerzo de Intel para proporcionar una amplia gama de infraestructura de IA, la compañía anunció una tarjeta de interfaz de red de IA para adaptadores de red Intel Ethernet y IPU Intel. Las tarjetas de interfaz de red de IA, que ya utiliza Google Cloud, proporcionarán una forma segura de descargar funciones como almacenamiento, redes y gestión de contenedores y gestionar la infraestructura de IA, dijo Intel. La intención es poder entrenar y ejecutar inferencias sobre los modelos de IA generativa cada vez más grandes que Intel predice que las organizaciones querrán implementar en todo Ethernet. Intel está trabajando con el Consorcio Ultra Ethernet para crear un estándar abierto para redes de IA a través de Ethernet. Se espera que las tarjetas de interfaz de red de IA estén disponibles en 2026. Una estrategia de sistemas escalables de amplio alcance tiene como objetivo facilitar la adopción de la IA. Para prepararse para lo que la compañía predice que será el futuro de la IA, Intel planea implementar una estrategia de sistemas escalables. para empresas. «Queremos que sea abierto y que las empresas tengan opciones en hardware, software y aplicaciones», dijo Sachin Katti, vicepresidente senior y gerente general de Network and Edge Group de Intel, en la sesión informativa previa. Para lograrlo, la estrategia de sistemas escalables proporciona productos Intel para todos los segmentos de IA dentro de la empresa: hardware, software, marcos y herramientas. Intel está trabajando con una variedad de socios para hacer realidad esta estrategia, incluido: Google Cloud. Tales. Cohesidad. NAVER. Bosco. Ola/Kutrim. NielsenIQ. Buscador. FIB. Grupo CtrlS. Aterrizando IA. Roboflujo. Intel predice un futuro de agentes y funciones de IA. Katti dijo en el informe previo que las empresas se encuentran en una era de copilotos de IA. Luego podría venir una era de agentes de IA, que puedan coordinar otras IA para realizar tareas de forma autónoma, seguida de una era de funciones de IA. El aumento de las funciones de IA podría significar que grupos de agentes asuman el trabajo de un departamento completo, dijo Sachin. VER: Articul8, creadores de una plataforma de software de inteligencia artificial generativa, se separó de Intel en enero. (TechRepublic) Competidores de Intel Intel está tratando de diferenciarse de sus competidores centrándose en la interoperabilidad en el ecosistema abierto. Intel compite en el espacio de los chips de IA con: NVIDIA, que anunció el chip Blackwell de próxima generación en marzo de 2024. AMD, que en febrero de 2024 anunció una nueva solución arquitectónica para la inferencia de IA basada en procesadores AMD Ryzen Embedded. Intel compite por el dominio en la fabricación de chips con Taiwan Semiconductor Manufacturing Co., Samsung, IBM, Micron Technologies, Qualcomm y otros. TechRepublic cubre Intel Vision de forma remota.

El término «copiloto» para los asistentes de IA parece estar en todas partes en el software empresarial actual. Como muchas cosas en la industria de la IA generativa, la forma en que se usa la palabra está cambiando. A veces se escribe con mayúscula y otras no. La elección de Copilot por parte de GitHub como marca fue el primer uso importante, seguido de que Microsoft nombrara a su asistente insignia de IA Copilot. Luego, el término copiloto rápidamente se volvió genérico. En el uso común, un copiloto de IA es un asistente de IA generativa, generalmente un modelo de lenguaje grande entrenado para una tarea específica. La confusión sobre un término podría llevar a que algunos clientes no sepan si lo que están adquiriendo es un producto de Microsoft, por ejemplo. Pero Microsoft no parece estar buscando apropiarse de la palabra copiloto, como la usan muchas otras compañías. El término copiloto se originó en el vuelo e implica una mano derecha competente para un profesional altamente calificado. Esto es lo que necesita saber sobre algunas de las muchas variedades de copiloto de IA. ¿Qué es el copiloto de Microsoft? Microsoft Copilot es un término general para una variedad de productos de IA generativa y chatbot que ahora están disponibles en todo el software de productividad de Microsoft. Para los usuarios empresariales, tenemos una guía para diferenciar las diversas iteraciones de Microsoft Copilot y las nuevas funciones e integraciones de Copilot. Microsoft utiliza dos construcciones para los nombres de productos Copilot: «en» o «para». En la hoja de trucos de TechRepublic sobre Microsoft Copilot, tenga en cuenta Copilot para seguridad y Copilots para finanzas, ventas y servicios, que probablemente se compren por separado para usos o departamentos específicos. Este es un caso interesante en el que Microsoft usa su propia marca de dos maneras a la vez (incluso después de todo el cambio de nombre de Copilot): los Copilots ofrecen capacidades muy similares, pero más específicas de la industria, en comparación con los Copilots en, por ejemplo. Por ejemplo, Copilot en Word puede ayudar con cualquier tarea de escritura, mientras que Copilot for Security se integra con productos de seguridad específicos. VER: Copilot en Bing solía llamarse Bing Chat antes de que Microsoft unificara un poco sus marcas. (TechRepublic) ¿Qué es GitHub Copilot? GitHub lanzó su producto Copilot en 2021 (GitHub ya había sido adquirido por Microsoft en ese momento). GitHub Copilot genera código basado en el código existente de un desarrollador; Está pensado como una versión AI de la programación en pareja. El GitHub Copilot original se construyó sobre OpenAI Codex, una variante del entonces actual GPT-3. GitHub cerró el círculo de la IA generativa con la incorporación de un chatbot a su versión más reciente, GitHub Copilot X. Más cobertura de IA de lectura obligada Microsoft Copilot vs GitHub Copilot Microsoft Copilot y GitHub Copilot tienen diferentes casos de uso principales. GitHub Copilot es específicamente para codificar, mientras que Microsoft Copilot se integra con una gran cantidad de software empresarial diferente. GitHub Copilot lee código, no lenguaje natural, y lo integra en un editor de código; Microsoft Copilot utiliza lenguaje natural y se integra con una variedad de productos de Microsoft. Por otro lado, Microsoft Copilot se puede utilizar para escribir código en algunos casos, como en Power Pages cuando se integra con Visual Studio Code. Microsoft Copilot para empresas comienza en $30,00 por usuario por mes con una licencia de Microsoft 365 Business Standard o Microsoft 365 Business Premium. GitHub Copilot comienza en $10 por usuario por mes. ¿Cuáles son otros productos Copilot? Salesforce no es un defensor de Microsoft de Copilot como marca. Einstein Copilot, lanzado en febrero de 2024, funciona en las ofertas de software como servicio de gestión de relaciones con clientes, inteligencia artificial y nube de datos de Salesforce. La empresa de software de automatización de procesos empresariales Appian llama Copilot a su compañero de IA generativa. Una empresa de software de prospección de ventas se llamó Copilot AI, pero no vende un robot de IA generativa; en cambio, ofrece respuestas predictivas a las conversaciones y campañas de LinkedIn. Hay muchas más empresas que utilizan Copilot para indicar un impulso generativo de IA para sus servicios. VER: Hay varias razones por las que las empresas o los usuarios individuales podrían querer desactivar las funciones de Microsoft Copilot que vienen con Windows 11. (TechRepublic) ¿Se puede utilizar copiloto como término genérico? Por ahora, “copilot” es una palabra flexible para productos de chatbot de IA genéricos y específicos de marca para usos comerciales específicos. Por ejemplo, Microsoft Copilot es un copiloto. A qué se refiere «copiloto» o cómo se denomina un chatbot de IA puede ser diferente según la organización. Los usos comunes del término indican el período del Salvaje Oeste de la IA en el que nos encontramos, y muestran que los profesionales todavía están trabajando en formas de utilizar la IA generativa para los negocios y que la IA generativa se está asentando en un papel de «asistente» en forma de chatbots personalizados. a productos y aplicaciones específicos. Probablemente verá la palabra copiloto escrita en minúsculas para indicar la versión genérica de los asistentes de IA. Las personas que crean la infraestructura Copilot en mayúsculas también han adoptado la versión genérica del término: el CEO de NVIDIA, Jensen Huang, utilizó copiloto como término genérico en NVIDIA GTC, al igual que muchas empresas en la sala de exposiciones de la conferencia. Otras empresas parecen mantenerse alejadas del término: IBM llama Asistente a su compañero de IA watsonx, al igual que Databricks con su Asistente Databricks.

Video Friday es tu selección semanal de increíbles videos de robótica, recopilados por tus amigos de IEEE Spectrum Robotics. También publicamos un calendario semanal de los próximos eventos de robótica para los próximos meses. Envíenos sus eventos para su inclusión.Eurobot Open 2024: 8–11 de mayo de 2024, LA ROCHE-SUR-YON, FRANCIAICRA 2024: 13–17 de mayo de 2024, YOKOHAMA, JAPÓNRoboCup 2024: 17–22 de julio de 2024, EINDHOVEN, PAÍSES BAJOSDisfrute de los videos de hoy !Vea el viaje de NVIDIA desde ser pionero en hardware avanzado para vehículos autónomos y herramientas de simulación hasta percepción y manipulación aceleradas para robots móviles autónomos y brazos industriales, culminando en la próxima ola de IA de vanguardia para robots humanoides.[ NVIDIA ]En la versión 4.0, mejoramos las habilidades de locomoción de Spot gracias al poder del aprendizaje por refuerzo. Paul Domanico, ingeniero en robótica de Boston Dynamics, habla de cómo el enfoque híbrido de Spot de combinar el aprendizaje por refuerzo con el control predictivo del modelo crea un robot aún más estable en los entornos más antagónicos.[ Boston Dynamics ]Estamos entusiasmados de compartir nuestro último progreso en la enseñanza de habilidades de propósito general a los EVE. Todo en el video es autónomo, todo a velocidad 1X, todo controlado con un único conjunto de pesos de red neuronal.[ 1X ]Lo que encuentro interesante acerca de que el Unitree H1 haga un giro de pie es dónde decide poner sus piernas.[ Unitree ]En la Exposición MODEX de marzo de 2024, Pickle Robot demostró cómo recoger carga de una pila aleatoria similar a lo que se ve en un remolque de camión desordenado después de haber rebotado durante muchos kilómetros de carretera. Las pilas de cajas nunca volvieron a ser las mismas y la manifestación se realizó en vivo frente a una multitud de espectadores 25 veces durante 4 días. Ningún otro sistema robótico de descarga de contenedores o remolques ha demostrado todavía esta capacidad de recoger pilas no estructuradas.[ Pickle ]RunRu es un robot parecido a un coche, un coche parecido a un robot, con autonomía, sociabilidad y operatividad. Se trata de un nuevo tipo de vehículo personal que pretende crear una relación “Jinba-Ittai” con sus pasajeros, que no sólo son siempre asertivos, sino que a veces también se quejan.[ ICD-LAB ]Verdie fue al GTC este año y se ganó el corazón de la gente, pero tal vez no el de los otros robots.[ Electric Sheep ]“DEEPRobotics AI+” combina capacidades de IA con sistemas de software robóticos para impulsar continuamente la inteligencia incorporada. El logro mostrado es el resultado del entrenamiento de un nuevo sistema de software e inteligencia artificial.[ DEEP Robotics ]Si desea recopilar datos para el agarre del robot, usar Stretch y un par de pinzas es lo más asequible posible.[ Hello Robot ]La verdadera razón por la que las piernas de Digit miran hacia atrás es para que no se golpee las espinillas al sacar las GPU del horno. Mientras tanto, algunos de nosotros podemos hornear nuestras GPU sin siquiera necesitar un horno.[ Agility ]P1 es el innovador robot bípedo de pie puntiagudo de LimX Dynamics, que sirve como una plataforma importante para el desarrollo sistemático y las pruebas modulares del aprendizaje por refuerzo. Se utiliza para avanzar en la investigación y la iteración de las habilidades básicas de locomoción bípeda. El éxito de P1 en la conquista del terreno forestal es un testimonio de la investigación y el desarrollo sistemático de LimX Dynamics en el aprendizaje por refuerzo.[ LimX ]Y ahora, esto.[ Suzumori Endo Lab ]Cocinar en las cocinas es divertido. ¡PERO hacerlo en colaboración con dos robots es aún más satisfactorio! Presentamos MOSAIC, un marco modular que coordina múltiples robots para colaborar estrechamente y cocinar con los humanos a través de la interacción del lenguaje natural y un depósito de habilidades.[ Cornell ]neoDavid es un humanoide robusto con diestras habilidades de manipulación, desarrollado en DLR. El objetivo principal en el desarrollo de neoDavid es acercarse lo más posible a las capacidades humanas, especialmente en términos de dinámica, destreza y robustez.[ DLR ]Bienvenido a nuestra serie de videos destacados para clientes donde mostramos algunos de los robots notables en los que nuestros clientes han estado trabajando. En este episodio, mostramos tres UGV de Clearpath Robotics que nuestros clientes utilizan para crear asistentes robóticos para tres aplicaciones diferentes.[ Clearpath ]Este vídeo presenta la nueva mano robótica de tres dedos de KIMLAB, que cuenta con sensores táctiles suaves para mejorar las capacidades de agarre. Aprovechando materiales de impresión 3D rentables, garantiza robustez y eficiencia operativa.[ KIMLAB ]Varios enfoques de planificación conscientes de la percepción han intentado mejorar la precisión de la estimación del estado durante las maniobras, mientras que a menudo se ha pasado por alto la compatibilidad de características entre marcos, un factor crucial que influye en la precisión de la estimación. En este artículo, presentamos APACE, un marco de generación de trayectorias ágil y consciente de la percepción para vuelos agresivos con quadrotores, que tiene en cuenta la compatibilidad de características durante la planificación de trayectorias.[ Paper ] a través de [ HKUST ]En este vídeo, vemos a Samuel Kunz, el piloto del equipo RSL Assistance Robot Race de ETH Zurich, mientras participa en los CYBATHLON Challenges 2024. Samuel completó las cuatro tareas designadas: recuperar un paquete de un buzón, usar un cepillo de dientes, colgar una bufanda en un tendedero y vaciar un lavavajillas, con la ayuda de un robot asistente. Logró una puntuación perfecta de 40 sobre 40 puntos y consiguió el primer puesto en la carrera, completando las tareas en 6,34 minutos.[ CYBATHLON ]Florian Ledoux es un fotógrafo de vida silvestre con un profundo amor por el Ártico y su vida silvestre. Usando el Mavic 3 Pro, pisa el hielo listo para capturar la belleza pura y las historias de este lugar frío y remoto.[ DJI ]
Source link
Con el anuncio de NVIDIA de AI Enterprise 5.0 y NVIDIA Inference Microservices en la conferencia GTC, el CEO Jensen Huang planea comenzar una era para hacer que la implementación de AI empresarial sea más fácil y más aplicable que nunca, posiblemente mientras cambia la forma principal en que las personas interactúan con las computadoras. La idea de controlar y programar computadoras solo con indicaciones es similar a lo que Humane ha propuesto con su Ai Pin basado en indicaciones, pero Huang la extiende a los desarrolladores y TI, así como a los consumidores: “El trabajo de la computadora es no requerir C++ para será útil”, afirmó Huang durante la sesión de preguntas y respuestas de prensa de NVIDIA GTC celebrada el 19 de marzo en San José, California (Figura A). Figura A El director ejecutivo de NVIDIA, Jensen Huang, habla durante una sesión de preguntas y respuestas con la prensa durante el NVIDIA GTC en San José, California, el 19 de marzo. Imagen: Megan Crouse/TechRepublic El director ejecutivo de NVIDIA, Jensen Huang, habla durante una sesión de preguntas y respuestas con la prensa durante el NVIDIA GTC en San José, California, el 19 de marzo. Imagen: Megan Crouse/TechRepublic Huang: La ingeniería rápida está transformando la programación Cuando se le preguntó si la programación seguirá siendo una habilidad útil en la era de las indicaciones generativas de IA, Huang dijo: «Creo que la gente debería aprender todo tipo de habilidades» y comparó el código. hasta hacer malabares, tocar el piano o aprender cálculo. Sin embargo, Huang dijo: «La programación no será esencial para que usted sea una persona exitosa». VER: Huang anunció una amplia gama de productos NVIDIA para centros de datos, inteligencia artificial empresarial, criptografía y más durante el discurso de apertura de la conferencia GTC. (TechRepublic) La IA generativa, dijo Huang, está “cerrando la brecha tecnológica. No es necesario ser programador de C++ para tener éxito”, afirmó. “Solo hay que ser un ingeniero rápido. ¿Y quién no puede ser un ingeniero puntual? Cuando mi esposa me habla, rápidamente me manipula. … Todos necesitamos aprender a incitar a las IA, pero eso no es diferente a aprender a incitar a los compañeros de equipo”. Huang continuó diciendo: «Pero si alguien quiere aprender a hacerlo (programar), que lo haga porque estamos contratando programadores». PREMIUM: aprenda cómo convertirse en un ingeniero rápido en esta descarga Premium de TechRepublic La ingeniería rápida es una habilidad que cambia rápidamente. ¿La ingeniería rápida reemplazará la programación tradicional cuando se trata de crear IA generativa a partir de IA generativa como sugirió Huang? «No dejaría mi trabajo diario todavía para convertirme en un ingeniero rápido», dijo Chirag Dekate, analista de Gartner, en una llamada a TechRepublic el 19 de marzo. «Desafortunadamente, el mercado se está corrigiendo excesivamente». Y el mercado se está sobrecorregindo ante un aumento en la demanda de lo que solía ser la ingeniería rápida. En una industria que cambia rápidamente, optimizar las indicaciones para lograr que una IA genere el texto correcto puede que ya no sea la forma en que se realiza la ingeniería de indicaciones de IA; en cambio, las indicaciones pueden ser multimodales. Los NIM son notables, dijo Dekate, porque encajan perfectamente la IA generativa en el contexto de multinube híbrida en el que operan muchas empresas. «Lo que NVIDIA está construyendo ahora es una base para las empresas nativas de IA de próxima generación, donde donde quiera que vayan las empresas experimentarán NIM», dijo. Sin embargo, es posible que NVIDIA no sea la empresa que haga realidad la transformación. Dekate señaló a Cognition AI, que la semana pasada presentó a Devin, su “ingeniero de software de IA”, como una señal de que la forma en que se realiza la ingeniería de software puede cambiar en el futuro. Más cobertura de IA de lectura obligada No importa qué nombre termine en el software más común, Dekate dijo que la forma en que los desarrolladores interactúan con la IA generativa cambiará rápidamente. «El ritmo de innovación de la IA generativa continúa acelerándose», afirmó Dekate. “Lo más probable es que no interactuemos con ninguno de estos modelos utilizando nuestras percepciones heredadas. Me refiero a tecnología de hace tres o seis meses como legado. La IA generativa cambia así de rápido”. David Nicholson, director de investigación de The Futurum Group, dijo a TechRepublic por correo electrónico que en un futuro de IA generativa «una instalación con lenguaje humano se convierte en una habilidad informática importante». “Tu título en inglés (o) historia o derecho de repente te ayuda a convertirte en un ingeniero rápido, pero una especialización en ciencias de la computación nunca estará de más”, escribió Nicholson. “No es una exageración de NVIDIA. Es verdaderamente una revolución”. Descargo de responsabilidad: NVIDIA pagó mi pasaje aéreo, alojamiento y algunas comidas para el evento NVIDIA GTC que se llevó a cabo del 18 al 21 de marzo en San José, California.
La plataforma GPU más nueva de NVIDIA es Blackwell (Figura A), que empresas como AWS, Microsoft y Google planean adoptar para la IA generativa y otras tareas informáticas modernas, anunció el CEO de NVIDIA, Jensen Huang, durante el discurso de apertura en la conferencia NVIDIA GTC el 18 de marzo en San José, California. Figura A La arquitectura NVIDIA Blackwell. Imagen: Los productos basados en NVIDIA Blackwell ingresarán al mercado de los socios de NVIDIA en todo el mundo a fines de 2024. Huang anunció una larga lista de tecnologías y servicios adicionales de NVIDIA y sus socios, hablando de la IA generativa como solo una faceta de la computación acelerada. «Cuando te aceleras, tu infraestructura son las GPU CUDA», dijo Huang, refiriéndose a CUDA, la plataforma informática paralela y el modelo de programación de NVIDIA. «Y cuando eso sucede, es la misma infraestructura que para la IA generativa». Blackwell permite el entrenamiento y la inferencia de modelos de lenguaje grandes. La plataforma Blackwell GPU contiene dos matrices conectadas por una interconexión de chip a chip de 10 terabytes por segundo, lo que significa que cada lado puede funcionar esencialmente como si «las dos matrices pensaran que es un solo chip», dijo Huang. Tiene 208 mil millones de transistores y se fabrica utilizando el proceso TSMC 4NP de 208 mil millones de NVIDIA. Cuenta con un ancho de banda de memoria de 8 TB/S y 20 pentaFLOPS de rendimiento de IA. Para las empresas, esto significa que Blackwell puede realizar entrenamiento e inferencia para modelos de IA escalando hasta 10 billones de parámetros, dijo NVIDIA. Blackwell se ve reforzado por las siguientes tecnologías: La segunda generación de TensorRT-LLM y NeMo Megatron, ambas de NVIDIA. Marcos para duplicar el tamaño de cálculo y modelo en comparación con el motor transformador de primera generación. Computación confidencial con protocolos de cifrado de interfaz nativos para privacidad y seguridad. Un motor de descompresión dedicado para acelerar consultas de bases de datos en análisis de datos y ciencia de datos. En cuanto a la seguridad, Huang dijo que el motor de confiabilidad “realiza una autoprueba, una prueba dentro del sistema, de cada bit de memoria en el chip Blackwell y de toda la memoria conectada a él. Es como si enviáramos el chip Blackwell con su propio probador”. Los productos basados en Blackwell estarán disponibles a través de proveedores de servicios de nube asociados, empresas del programa NVIDIA Cloud Partner y nubes soberanas seleccionadas. La línea de GPU Blackwell sigue a la línea de GPU Grace Hopper, que debutó en 2022 (Figura B). NVIDIA dice que Blackwell ejecutará IA generativa en tiempo real en LLM de billones de parámetros a un costo 25 veces menor y un consumo de energía menor que la línea Hopper. Figura B El director ejecutivo de NVIDIA, Jensen Huang, muestra las GPU Blackwell (izquierda) y Hopper (derecha) en NVIDIA GTC 2024 en San José, California, el 18 de marzo. Imagen: Megan Crouse/TechRepublic El superchip NVIDIA GB200 Grace Blackwell conecta varias GPU Blackwell junto con el Blackwell GPUs, la compañía anunció el superchip NVIDIA GB200 Grace Blackwell, que vincula dos GPU NVIDIA B200 Tensor Core a la CPU NVIDIA Grace, proporcionando una nueva plataforma combinada para la inferencia LLM. El Superchip NVIDIA GB200 Grace Blackwell se puede vincular con las plataformas Ethernet NVIDIA Quantum-X800 InfiniBand y Spectrum-X800 recientemente anunciadas por la compañía para velocidades de hasta 800 GB/S. El GB200 estará disponible en NVIDIA DGX Cloud y a través de instancias de AWS, Google Cloud y Oracle Cloud Infrastructure a finales de este año. El nuevo diseño de servidor mira hacia modelos de IA de billones de parámetros El GB200 es un componente del recientemente anunciado GB200 NVL72, un diseño de servidor a escala de rack que incluye 36 CPU Grace y 72 GPU Blackwell para 1,8 exaFLOP de rendimiento de IA. NVIDIA espera posibles casos de uso para LLM masivos de billones de parámetros, incluida la memoria persistente de conversaciones, aplicaciones científicas complejas y modelos multimodales. El GB200 NVL72 combina la quinta generación de conectores NVLink (5000 cables NVLink) y el superchip GB200 Grace Blackwell para obtener una enorme cantidad de potencia informática que Huang llama «un sistema de IA exoflops en un solo bastidor». «Eso es más que el ancho de banda promedio de Internet… básicamente podríamos enviar todo a todo el mundo», dijo Huang. «Nuestro objetivo es reducir continuamente el coste y la energía (están directamente relacionados entre sí) de la informática», afirmó Huang. Para enfriar el GB200 NVL72 se necesitan dos litros de agua por segundo. La próxima generación de NVLink ofrece una arquitectura de centro de datos acelerada. La quinta generación de NVLink proporciona un rendimiento bidireccional de 1,8 TB/s por comunicación GPU entre hasta 576 GPU. Esta iteración de NVLink está pensada para utilizarse en los LLM complejos más potentes disponibles en la actualidad. «En el futuro, los centros de datos serán considerados como una fábrica de inteligencia artificial», dijo Huang. Presentación de los microservicios de inferencia de NVIDIA Otro elemento de la posible «fábrica de IA» es el microservicio de inferencia de NVIDIA, o NIM, que Huang describió como «una nueva forma de recibir y empaquetar software». Los NIM de NVIDIA son microservicios que contienen API, código específico de dominio, motores de inferencia optimizados y tiempo de ejecución empresarial necesarios para ejecutar IA generativa. Estos microservicios nativos de la nube se pueden optimizar según la cantidad de GPU que utiliza el cliente y se pueden ejecutar en la nube o en un centro de datos propio. Los NIM permiten a los desarrolladores utilizar API, NVIDIA CUDA y Kubernetes en un solo paquete. VER: Python sigue siendo el lenguaje de programación más popular según el índice TIOBE. (TechRepublic) Los NIM aprovechan la IA para crear IA, simplificando parte del trabajo pesado, como la inferencia y la capacitación, necesarios para crear chatbots. A través de bibliotecas CUDA de dominio específico, los NIM se pueden personalizar para industrias muy específicas, como la atención médica. En lugar de escribir código para programar una IA, dijo Huang, los desarrolladores pueden “reunir un equipo de IA” que trabajen en el proceso dentro del NIM. «Queremos construir chatbots (copilotos de IA) que funcionen junto con nuestros diseñadores», dijo Huang. Los NIM estarán disponibles a partir del 18 de marzo. Los desarrolladores pueden experimentar con los NIM sin costo alguno y ejecutarlos a través de una suscripción a NVIDIA AI Enterprise 5.0. Los NIM están disponibles en Amazon SageMaker, Google Kubernetes Engine y Microsoft Azure AI, y pueden interoperar con los marcos de IA Deepset, LangChain y LlamaIndex. Nuevas herramientas lanzadas para NVIDIA AI Enterprise en la versión 5.0 NVIDIA lanzó la versión 5.0 de AI Enterprise, su plataforma de implementación de IA destinada a ayudar a las organizaciones a implementar productos de IA generativa para sus clientes. 5.0 de NVIDIA AI Enterprise agrega lo siguiente: NIM. Microservicios CUDA-X para una amplia variedad de casos de uso de IA acelerada por GPU. AI Workbench, un conjunto de herramientas para desarrolladores. Soporte para la plataforma Red Hat OpenStack. Soporte ampliado para nuevas GPU NVIDIA, hardware de red y software de virtualización. El operador de modelo de lenguaje grande de generación aumentada de recuperación de NVIDIA se encuentra ahora en acceso temprano para AI Enterprise 5.0. AI Enterprise 5.0 está disponible a través de Cisco, Dell Technologies, HP, HPE, Lenovo, Supermicro y otros proveedores. Otros anuncios importantes de NVIDIA en GTC 2024 Huang anunció una amplia gama de nuevos productos y servicios en computación acelerada e inteligencia artificial generativa durante el discurso de apertura de NVIDIA GTC 2024. NVIDIA anunció cuPQC, una biblioteca utilizada para acelerar la criptografía poscuántica. Los desarrolladores que trabajan en criptografía poscuántica pueden comunicarse con NVIDIA para obtener actualizaciones sobre la disponibilidad. La serie X800 de conmutadores de red de NVIDIA acelera la infraestructura de IA. En concreto, la serie X800 contiene los conmutadores Ethernet NVIDIA Quantum-X800 InfiniBand o NVIDIA Spectrum-X800, el conmutador NVIDIA Quantum Q3400 y el NVIDIA ConnectXR-8 SuperNIC. Los conmutadores X800 estarán disponibles en 2025. Las principales asociaciones detalladas durante la conferencia magistral de NVIDIA incluyen: La plataforma de IA de pila completa de NVIDIA estará en Enterprise AI de Oracle a partir del 18 de marzo. AWS brindará acceso a las instancias Amazon EC2 basadas en GPU NVIDIA Grace Blackwell y a NVIDIA DGX Cloud con seguridad Blackwell. NVIDIA acelerará Google Cloud con la plataforma informática NVIDIA Grace Blackwell AI y el servicio NVIDIA DGX Cloud, que llegarán a Google Cloud. Google aún no ha confirmado una fecha de disponibilidad, aunque es probable que sea a finales de 2024. Además, la plataforma DGX Cloud con tecnología NVIDIA H100 estará disponible de forma general en Google Cloud a partir del 18 de marzo. Oracle utilizará NVIDIA Grace Blackwell en su OCI Supercluster, OCI Compute y NVIDIA DGX Cloud en Oracle Cloud Infrastructure. Algunos servicios soberanos de IA combinados de Oracle y NVIDIA estarán disponibles a partir del 18 de marzo. Microsoft adoptará el Superchip NVIDIA Grace Blackwell para acelerar Azure. Se puede esperar la disponibilidad más adelante en 2024. Dell utilizará la infraestructura de inteligencia artificial y el paquete de software de NVIDIA para crear Dell AI Factory, una solución empresarial de inteligencia artificial de extremo a extremo, disponible a partir del 18 de marzo a través de canales tradicionales y Dell APEX. En un momento futuro no revelado, Dell utilizará el superchip NVIDIA Grace Blackwell como base para una arquitectura de refrigeración líquida, de alta densidad y a escala de rack. El Superchip será compatible con los servidores PowerEdge de Dell. SAP agregará capacidades de generación aumentada de recuperación de NVIDIA a su copiloto Joule. Además, SAP utilizará NIM de NVIDIA y otros servicios conjuntos. «Toda la industria se está preparando para Blackwell», dijo Huang. Competidores de los chips de IA de NVIDIA NVIDIA compite principalmente con AMD e Intel en lo que respecta al suministro de IA empresarial. Qualcomm, SambaNova, Groq y una amplia variedad de proveedores de servicios en la nube juegan en el mismo espacio en lo que respecta a la inferencia y el entrenamiento de IA generativa. AWS tiene sus propias plataformas de inferencia y formación: Inferentia y Trainium. Además de asociarse con NVIDIA en una amplia variedad de productos, Microsoft tiene su propio chip de inferencia y entrenamiento de IA: el Maia 100 AI Accelerator en Azure. Descargo de responsabilidad: NVIDIA pagó mi pasaje aéreo, alojamiento y algunas comidas para el evento NVIDIA GTC que se llevó a cabo del 18 al 21 de marzo en San José, California.
En el discurso de apertura del lunes en el evento GTC 2024 de Nvidia, el director ejecutivo Jenson Huang siguió repitiendo la frase «fábrica de IA». «En la última Revolución Industrial, la materia prima que entraba en la fábrica era agua», dijo Huang a TechCrunch en una entrevista después del discurso de apertura. “Y el producto fue la electricidad”. Estaba comparando esto (convertir materia prima en algo más que tenga valor) con la noción de centros de datos, que son puramente pozos de dinero. “Está ocurriendo una nueva Revolución Industrial en estos [server] Habitaciones: yo las llamo fábricas de IA”, dijo Huang. “La materia prima que entra son datos y electricidad. Lo que sale de ahí son tokens de datos. El token es invisible y se distribuirá por todo el mundo. Es muy valioso”. La distinción tiene mucho sentido en un mundo donde Nvidia se beneficia enormemente si puede persuadir a las empresas a pensar en los centros de datos y las herramientas de inteligencia artificial de una manera diferente. “La última vez, los centros de datos entraron en los centros de costos y gastos de capital de su empresa. Lo consideras un costo. Sin embargo, una fábrica es otra cosa. Genera dinero”, dijo. «El nuevo mundo de la IA generativa tiene una nueva forma de fábrica».
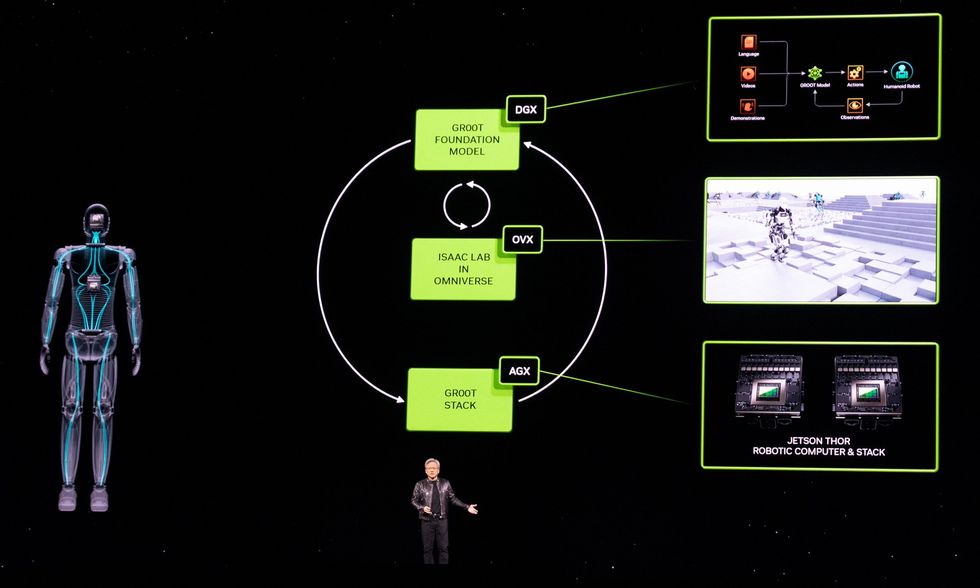
Como era de esperar, la actual conferencia de desarrolladores GTC de Nvidia en San José trata casi exclusivamente sobre IA este año. Pero entre los desarrollos de IA, Nvidia también ha hecho un par de anuncios importantes sobre robótica. Primero, está el Proyecto GR00T (con cada letra y número pronunciados individualmente para no provocar la ira de Disney), un modelo básico para robots humanoides. Y en segundo lugar, Nvidia se ha comprometido a ser el miembro fundador platino de Open Source Robotics Alliance, una nueva iniciativa de la Open Source Robotics Foundation destinada a garantizar que el sistema operativo de robot (ROS), una colección de bibliotecas de software de código abierto y herramientas, tiene el apoyo que necesita para prosperar.GR00TPrimero, hablemos de GR00T (abreviatura de “Tecnología Generalista Robot 00”). La forma en que los presentadores de Nvidia lo enunciaron letra por letra durante sus charlas sugiere claramente que en privado simplemente dicen «Groot». Así que, en lo que a mí respecta, el resto de nosotros también podemos decir simplemente «Groot». Como «modelo básico de propósito general para robots humanoides», el GR00T pretende proporcionar un punto de partida para que robots humanoides específicos realicen tareas específicas. Como es de esperar de algo que se presenta por primera vez en una conferencia magistral de Nvidia, es terriblemente vago en este momento y tendremos que profundizar en ello más adelante. Aquí encontrará prácticamente todo lo útil que Nvidia nos ha contado hasta ahora: “La construcción de modelos básicos para robots humanoides generales es uno de los problemas más interesantes de resolver en la IA hoy en día”, dijo Jensen Huang, fundador y director ejecutivo de NVIDIA. «Las tecnologías habilitadoras se están uniendo para que los principales especialistas en robótica de todo el mundo den pasos de gigante hacia la robótica general artificial». Los robots impulsados por GR00T… serán diseñados para comprender el lenguaje natural y emular movimientos mediante la observación de acciones humanas, aprendiendo rápidamente coordinación y destreza. y otras habilidades para navegar, adaptarse e interactuar con el mundo real. Esto suena bien, pero ese “será” supone mucho trabajo pesado. Aquí falta un “cómo” muy significativo. Más específicamente, necesitaremos una mejor comprensión de lo que subyace a este modelo básico: ¿hay datos reales de robots en alguna parte o se basan en una enorme cantidad de simulación? ¿Las empresas de robótica humanoide implicadas están aportando datos para mejorar GR00T o, por el contrario, entrenando sus propios modelos basándose en ellos? Es ciertamente notable que Nvidia mencione a la mayoría de los pesos pesados en humanoides comerciales, incluidos 1X Technologies, Agility Robotics, Apptronik, Boston Dynamics, Figure AI, Fourier Intelligence, Sanctuary AI, Unitree Robotics y XPENG Robotics. Podremos comunicarnos con algunas de esas personas directamente esta semana para, con suerte, obtener más información. En cuanto al hardware, Nvidia también anuncia una nueva plataforma informática llamada Jetson Thor:Jetson Thor fue creado como una nueva plataforma informática capaz de realizar tareas complejas e interactuar de forma segura y natural con personas y máquinas. Tiene una arquitectura modular optimizada en cuanto a rendimiento, potencia y tamaño. El SoC incluye una GPU de próxima generación basada en la arquitectura NVIDIA Blackwell con un motor transformador que ofrece 800 teraflops de rendimiento de IA de punto flotante de 8 bits para ejecutar modelos de IA generativa multimodal como GR00T. Con un procesador de seguridad funcional integrado, un grupo de CPU de alto rendimiento y 100 GB de ancho de banda Ethernet, simplifica significativamente los esfuerzos de diseño e integración. Hablando de la arquitectura Blackwell de Nvidia, hoy la compañía también presentó su GPU B200 Blackwell. Y para completar los anuncios, la fundición de chips TSMC y Synopsys, una empresa de automatización de diseño electrónico, dijeron que pondrán en producción la herramienta de litografía inversa de Nvidia, cuLitho. La Open Source Robotics AllianceEl otro gran anuncio es en realidad de Open Source Robotics Foundation, que está lanzando Open Source Robotics Alliance (OSRA), una “nueva iniciativa para fortalecer la gobernanza de nuestros proyectos de software de robótica de código abierto y garantizar la salud de la comunidad de Robot Operating System (ROS) Suite durante muchos años por venir. .” Nvidia es el miembro platino inaugural de OSRA, pero no está solo: otros miembros platino incluyen Intrinsic y Qualcomm. Otros miembros importantes incluyen Apex, Clearpath Robotics, Ekumen, eProsima, PickNik, Silicon Valley Robotics y Zettascale. [Open Source Robotics Foundation] Había planeado reestructurar sus operaciones ampliando la participación de la comunidad y expandiendo su impacto en el ecosistema ROS más amplio”, explica Vanessa Yamzon Orsi, directora ejecutiva de la Open Source Robotics Foundation. “La venta de [Open Source Robotics Corporation] fue el primer paso hacia esa visión, y el lanzamiento de OSRA es el siguiente gran paso hacia ese cambio”. Tuvimos tiempo para una breve sesión de preguntas y respuestas con Orsi para comprender mejor cómo afectará esto a la comunidad ROS en el futuro. Usted estructuró la OSRA para que tuviera una membresía mixta y un modelo meritocrático como la Fundación Linux. ¿Qué significa eso exactamente? Vanessa Yamzon Orsi: Hemos modelado la OSRA para permitir caminos hacia la participación en sus actividades a través de membresías pagas (para organizaciones y sus representantes) y los miembros de la comunidad que apoyan los proyectos a través de sus aportes. El modelo mixto permite la participación de la forma más adecuada para cada organización o individuo: contribuyendo con financiación como miembro pagador, contribuyendo directamente al desarrollo del proyecto, o ambos. ¿Cuáles son algunos de los beneficios para el ecosistema ROS que podemos esperar a través de OSRA?Orsi : Esperamos que OSRA beneficie los proyectos de OSRF de tres maneras significativas: proporcionando un flujo estable de financiación para cubrir el mantenimiento y el desarrollo del ecosistema ROS. Fomentando una mayor participación de la comunidad en el desarrollo a través de procesos abiertos y el logro de un estatus meritocrático y abierto. Al lograr una mayor participación de la comunidad en la gobernanza y garantizar que todas las partes interesadas tengan voz en la toma de decisiones. ¿Por qué será esto algo bueno para los usuarios de ROS? Orsi: La OSRA garantizará que ROS y el conjunto de proyectos de código abierto bajo la dirección de Open Robotics seguirá recibiendo apoyo y fortaleciéndose en los años venideros. Al proporcionar gobernanza y supervisión organizadas, caminos más claros hacia la participación comunitaria y apoyo financiero, proporcionará estabilidad y estructura a los proyectos y al mismo tiempo permitirá el desarrollo continuo. De los artículos de su sitio Artículos relacionados en la Web
Source link
Las capacidades de memoria están a punto de aumentar nuevamente… Pero en el lado de los portátiles. Micron ha anunciado que está trabajando en kits de memoria DDR5 SO-DIMM con 12 GB por módulo. DDR5 SO-DIMM: ¡capacidades de 12 GB por módulo de Micron! Desde la llegada de DDR5, las cosas se han vuelto locas rápidamente en lo que respecta a las capacidades de los módulos RAM. Hasta ahora, podíamos elegir entre 4 GB, 8 GB, 16 GB, etc. Sin embargo, recientemente hemos podido elegir módulos de 24 GB y 48 GB, las llamadas configuraciones «no binarias». Por supuesto, la ventaja reside en las capacidades de memoria mejoradas en comparación con los kits tradicionales. ¡Con una placa base con dos ranuras para RAM, por ejemplo, puedes obtener una configuración de 96 GB! En resumen, nos enteramos de que Micron también está planeando kits de memoria de este tipo en formato SO-DIMM, un formato comúnmente utilizado en portátiles en particular. Sin embargo, tendremos que conformarnos con kits de matriz de 12 GB. En términos de frecuencias, la memoria funcionaría a 5600 MT/s en su punto más rápido. También se ofrecerán versiones más lentas: 5200 MT/s y 4800 MT/s. En cuanto a los precios, se pueden encontrar varios kits en Amazon.co.uk, con un módulo de 12 GB a 5200 MT/s por 44,99 £ (52,64 €). El kit de 24 GB 5600 MT/s tiene un precio de 87,99 £ (102,94 €).